
An Empirical Evaluation of Real-Time Stream Processing Frameworks for Handling High Velocity Big Data
Keywords:
Stream, processing, framework, performance, latency, throughput model, Occupational health and safetyAbstract
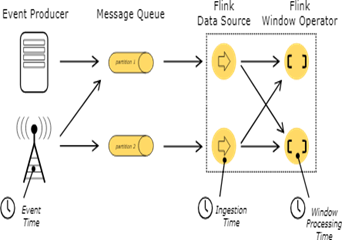
The exponential growth of data in motion, also known as streaming data or big data, has necessitated the development of specialized data processing platforms that can handle the volume, velocity and variety of such data in real-time. This study empirically evaluates three leading open-source, real-time stream processing frameworks – Apache Storm, Apache Spark Streaming, and Apache Flink – on critical performance metrics like throughput, latency and fault tolerance when applied to high velocity big data workloads. Six experiments were conducted using both synthetic and real-world streaming data to measure throughput and latency while scaling up cluster resources. Fault tolerance tests were performed by killing execution nodes and measuring system recovery times. Results indicate that Flink outperformed Storm and Spark Streaming in most tests, achieving up to 5 times higher throughput with half the latency, as well as sub-second recovery from failures. Storm showed the most inconsistent performance across experiments. We discuss the advantages and limitations of each framework and offer recommendations for selecting the right stream processing platform based on use case requirements around scalability, responsiveness and reliability. The empirical evaluations provided can serve as a practical guide for organizations planning production deployments of real-time analytics on fast data.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2022 International Journal of Business Intelligence and Big Data Analytics

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.